背景
人工智能,机器学习,深度学习,对抗网络这些名词逐渐深入人心,在社会的各个方面都有着AI技术的身影。但是真正了解这项技术的人才其实十分的缺乏。
目前AI技术大方向主要包含图像处理,信号处理,文本处理等等方面,在这些大方向之下,针对不同的行业,不同的需求逐渐形成了各个行业中自己独特的AI技术发展及应用方向。在很多领域中已经有了成熟的AI技术研究方向和产业体系,但是在安全领域还处于起步阶段,大家都在想着分一杯羹。
身为安全行业从业人员,更加体会到这个领域急需AI技术的帮助。因为在现在的互联网世界中,安全防御体系无时无刻不在应对新的挑战。哪怕是拥有丰富工作经验的安全从业者,在面对层出不穷的攻击手段和海量的日志数据时也会望洋兴叹。AI技术是这些问题天然契合的解决方案,特别是数据量指数级爆炸增长的信息时代,AI技术甚至会发展成为唯一的出路。
契机
由于本身就是信息安全专业毕业,算是根正苗红的科班出身。在AI技术横行的当代,在大学中天天接受这方面知识的熏陶,自然而然走上了AI + Security的道路。正好现工作的公司处于一个特殊的时期,也算是为之后的工作练练手打基础,利用机器学习实现了一个从源码角度检测Webshell脚本的简单系统。
现在传统的检测Webshell的方式无非特征检测或者规则库匹配,这样的检测方法有着很高的准确度,但是弊端也显而易见。永远追随着Webshell的脚步,对于新出现的Webshell无能为力。而且Webshell的特征库或者规则库各大安全公司或者厂商都有自己的资源,不会向公众开放,也不会共享。闭门造车自然会造成以偏概全,覆盖面小的问题。而AI技术检测Webshell则不存在这些问题,诚然目前这种检测Webshell的方式比特征检测的方式误报率更高,可是这只是样本数据量太小的问题,这个随着时间发展很简单就可以解决,将来的效果一定会远远超越传统方式。
成果
我基于NB算法实现了这样一款Webshell检测工具,具体用法在README.md文件中有解释,比较简单,只是自己学习一个副产物,仅做实验用,欢迎留言和我交流^。^
实现
设计思路
最初设计时有两种思路。第一种是处理ADFA-LD数据集那样的数据,ADFA-LD数据集记录的是系统调用序列,然后用数字标识每一个系统调用,这样可以得到一个系统调用序列。但是ADFA-LD数据集这样的数据限制太多,适用面太小,需要强大的设备或者技术对前期数据进行处理,所以放弃了这一种方法。最终选择的是第二种思路,借用自然语言处理技术,直接对源代码进行处理,适用面比较广,但是也存在一些问题,后面会详细叙述。
流程
处理的原始数据就是Webshell源码(php,asp,jsp格式):
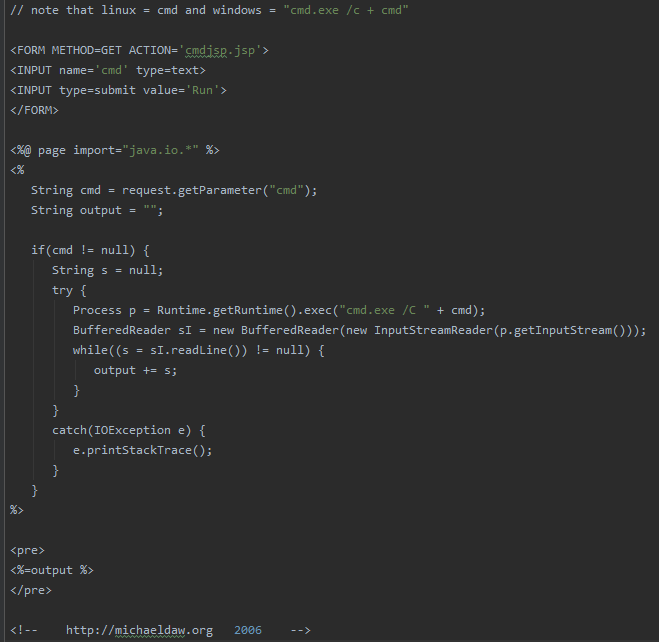
或是这样的一句话木马:
1 | <%execute request("include")%> |
1 | <pre><body bgcolor=white><? @system($_REQUEST["cmd"]); ?></body></pre> |
所以首先需要将文本数据读取出来,通过load_str(filepath)方法,把一个文件作为一个完整的字符串处理,过滤掉文件中的回车换行:
1 | def load_str(filepath): |
由于样本中可能存在大量的图片、JavaScript,所以遍历目录时需要过滤掉非我们想要的格式的文件。通过load_file(dir)方法递归实现:
1 | def load_files(dir): |
加载搜集到的Webshell脚本和其他开源软件源码分别作为黑,白样本,,并统计样本个数,将Webshell样本标记为1,正常的源码标记为0:
1 | webshell_files_list = load_files(webshell_dir) |
合并样本:
1 | x = webshell_files_list + normal_files_list |
本次使用自然语言处理方法中最常见最基础的2-Gram提取词袋模型,并使用TF-IDF进行处理:
1 | CV = CountVectorizer(ngram_range = (2, 2), decode_error = 'ignore', max_features = max_features, token_pattern = r'\b\w+\b', min_df = 1, max_df = 1.0) |
2-Gram算法是N-Gram算法的一种类型,简单理解就是截取相邻的每2个字符作为词袋。本次为了增加效率,将提取的词袋建立对应字典。
此时文本数据将被转换成数组,然后将处理后的数据投入训练,实例化一个模型,通过do_GNB(x, y)方法实现:
1 | def do_GNB(x, y): |
同时将训练好的模型保存为.pickle格式的文件,这样可以直接调用模型预测新的未知文件是否为Webshell脚本。不用每次都重新训练模型,增加效率。
结果展示
运行后的结果如下图所示:
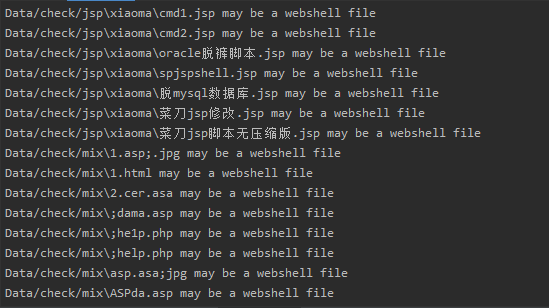
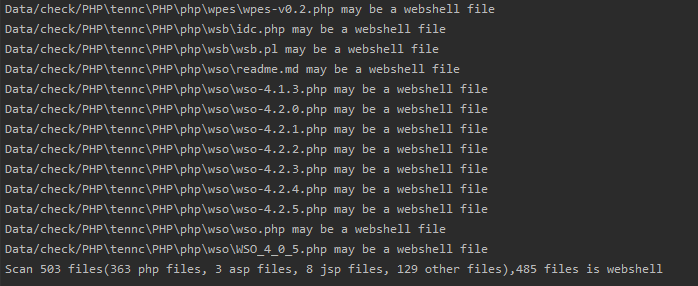
经过统计,准确度超过9成,同时误报率不超过1%。不过暂时手上的数据量比较少,所以实际情况中可能达不到预期的性能。
问题归总
问题一
前文说过设计思路上有个问题,其实就是现在很多Webshell脚本都是加密的,如何去分辨。对于这个问题也很好解释,正常的源码文件也不会费力的去加密,所以很多加密的文件确实本身就存在问题,值得我们好好的去分析。对于某些加密方式其实是在我们的知识库里的,可以考虑在数据处理的时候加一个简单的解密流程。但是不太推荐花费过多的精力和资源在解密上,这样会造成效率的低下。
问题二
这种方法优势很明显,就是能够让我们走在危险的前面,这在安全领域很可贵,但是不可避免的存在误报率的问题。对于这个问题,也有一些解决方法。一是不断的扩展样本集,其实样本对于AI技术很重要,对最终预测结果的准确度有很大的影响。其实这也是这种检测方法的一个优势,仅仅通过更加契合的样本集就能够大幅度的提高预测结果的准确度,同时降低误报率。二是在数据处理部分寻找更好的方法。本次采用的只是自然语言处理方面最普通的处理手段,随着AI技术的不断发展,一定会出现更多更好的数据处理技术。最后从来没有完美的技术,这种Webshell检测方法可以和传统方法结合,相信可以得到更好的结果。