简述
作为正在开发的态势感知产品中重要的一部分,初步实现了恶意URL的AI检测功能模块。该模块将集成到大数据平台的检测引擎中去,将对平台推过来的每一条URL进行检测,检测结果实时反馈回平台。
通过机器学习检测Web请求包中的URL/URI判断是否为恶意URL,暂时不做细分,只做笼统的考量,后期可以通过训练集中添加细分的样本数据重新构建能够细分详细攻击类型的模型,比如分辨SQL注入攻击,XSS攻击,恶意域名等。
模型生成完毕之后,将供大平台直接调用模型对每一个待检测数据包进行判断,生成基础事件。
关于不同类型的攻击模型,生成模型的代码基本都一样,主要差别在于使用的样本即训练集不一样,本次训练使用的是恶意URL的样本集,里面包含了SQL注入、恶意域名等。所以要想生成高精度的攻击检测模型,关键在于使用好的专用训练集。
处理数据
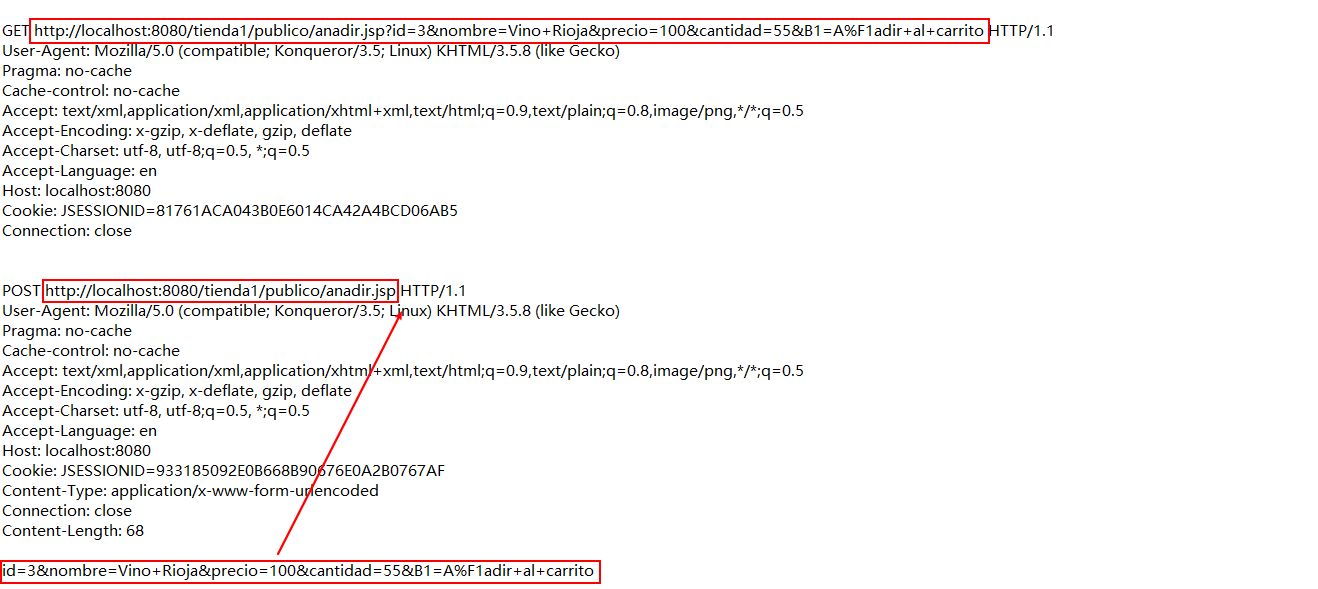
通过探针抓取到的数据会被解析成应用层json格式数据,通过分类处理不同method剥离出URI/URL作为待处理数据(P.S.对于GET数据直接将URI/URL作为分析对象,对于POST请求将URI/URL后面拼接上body中的数据字段作为分析对象)。
数据预处理及建模
处理对象为分离后的URI/URL,如下图所示:
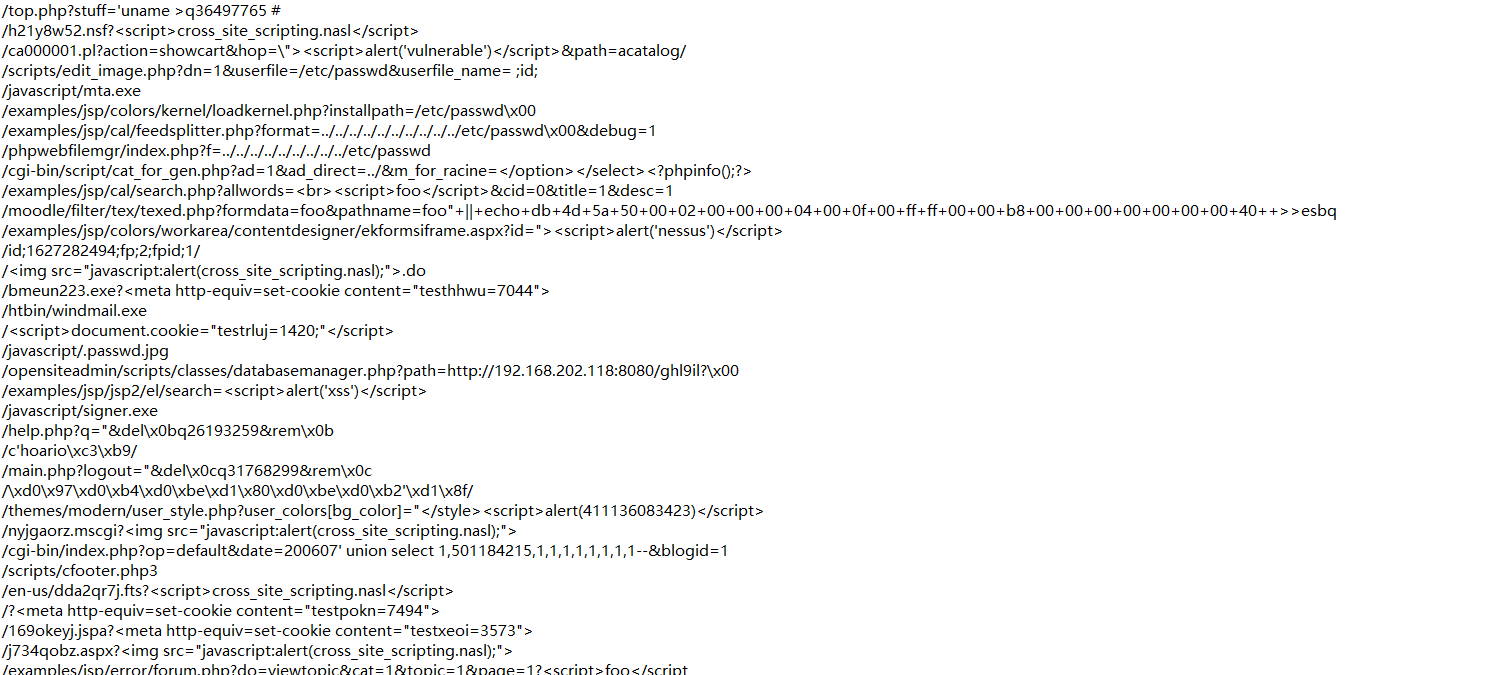
然后读取数据,并给黑白样本打上标签,切割文本,将文本数据转化为矩阵向量,通过TF-IDF方法提取特征,训练模型采取逻辑回归算法实现。
1 | def __init__(self): |
分割字符串通过自己定义的get_ngrams(self, query)方法实现:
1 | def get_ngrams(self, query): |
预测
预测的数据格式为:

预测通过predict(self, newQueries)方法实现:
1 | def predict(self, newQueries): |
预测的结果保存为json格式方便推回给大数据平台处理:

产品化工作
为了便于产品化的实现,设计了两种方法思路。刚开始尝试将整个数据的预处理,训练及建模过程写入一个类,然后将整个类序列化,保存为.pickle格式的文件,然后供大数据平台调用。后来为了增加数据处理的效率,仅仅将训练好的模型保存为.pmml格式的文件供大数据平台调用。
可能的改进
处理结果细化,将恶意请求再次具体细分为SQL注入,XSS攻击,恶意域名等。
在机器学习算法前提下,特征处理方法的改进,寻求优化TF-IDF方法方案。目前采用的是仅仅使用TF-IDF算法对数据进行预处理,后面可以考虑采用词袋+TF-IDF算法,或者结合TF-IDF算法将URL中不重要的部分进行泛化处理。
跳出机器学习算法,省去特征处理的过程,改用深度学习算法,构建神经网络(需要花费大量时间不断计算,调优)。
目前可以将同一个IP的一个时间段之内的URL请求同时进行预测,来判断该IP是否实施攻击,也可以只检测单条URL判断是否为恶意请求。未来可改进为不剥离请求包中IP标签,对一段时间内所有数据进行检测,分出有攻击行为的IP上报。