前言
Unlink机制的利用是堆溢出中很常见的手段,这里记录一下自己的理解。
原理
利用Unlink机制实现堆溢出攻击是通过对chunk进行布局,借助内存回收机制触发Unlink操作形成攻击。
首先了解一下Unlink操作。Unlink实现将一个双向链表中的空闲块拿出来,然后与目前物理相邻的chunk进行合并。
基本过程套用CTF Wiki的经典图示:
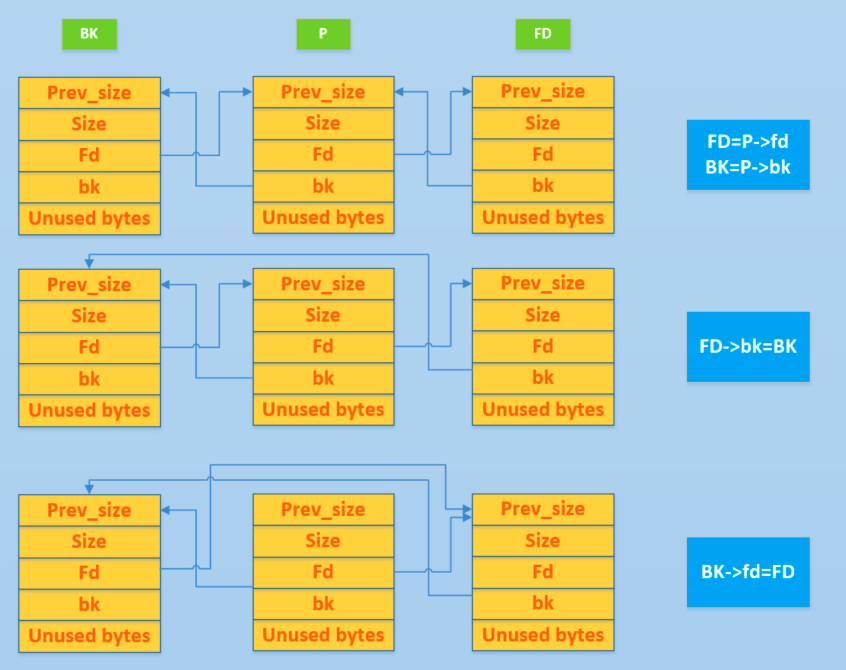
chunk的合并分为向前和向后合并,这里的前和后都是指在物理内存中的位置,而不是fd和bk链表所指的堆块。以当前chunk为基准,将previous free chunk合并到当前chunk称为向后合并,将next free chunk合并到当前chunk称为向前合并。
向后合并流程:
首先检测前一个chunk是否为free状态,通过检测previous chunk的PREV_INUSE(P)标志位,如果为0表示free状态。但内存中第一个申请的chunk的前一个chunk一般都被认为在使用中不会发生向后合并;
如果不是内存中的第一个chunk且它的前一个chunk标记为free状态时,发生向后合并;
首先修改chunk的size位大小为两个chunk size之和;
再将指针移动到前一个chunk处;
最后调用unlink将前一个chunk从它所在的链表中移除。
向前合并也会做相应的标志位检测,判断需要向前合并的时候,只改变size的大小,而不改变指针。
理想情况下的简单利用
以32位程序为例,如果有两个相邻的chunk,在第一个chunk写入数据的时候存在溢出。此时内存示意图:
1 | low address |
这时候我们将nextchunk的fd和bk指针修改为指定的值:size修改为-4即0xfffffffc,fd修改为target_addr - 12,bk修改为shellcode_addr。
覆盖后的内存示意图:
1 | low address |
当我们free第一个chunk的时候:
判断向前合并,此时由于第一个chunk的前一个chunk总是处于使用状态,即使根本不存在,故而转为判断向后合并;
判断的方法是检查下下个chunk的
PREV_ISUSE标志位。即当前chunk加上当前size得到下个chunk,下个chunk加上下个size得到下下个chunk,因为我们设置下个chunk大小为-4,则下个chunk的pre_size位置被认为是下下个chunk的开始,下个size位置是0xfffffffc标志未置位,被认为是free所以转而对后一个chunk采取Unlink操作。
此时根据上面Unlink操作的图示,一步一步分析下情况:
FD = P -> fd = target_addr - 12;BK = P -> bk = shellcode_addr;FD -> bk = BK,即P -> fd -> bk = BK,表示shellcode的地址被写进了P -> fd -> bk位置,而这里实际是P -> fd + 12的位置。因为P -> fd指向的是前一个chunk的头部,加12是跳过prev_size、size和fd,到达bk的位置。而P -> fd = target_addr - 12,所以shellcode_addr实际被写到了target_addr的位置;BK -> fd = FD,即P -> bk -> fd = FD,表示target_addr - 12被写到P -> bk -> fd位置,,而这里实际是P -> bk + 8的位置。因为P -> bk指向的是第二个chunk的头部,加8是跳过prev_size和size到达fd。而P -> bk + 8实际是shellcode_addr + 8的位置,即target_addr - 12被写到shellcode_addr + 8处。所以这里需要注意两点,一是需要确保shellcode_addr + 8地址具有可写的权限;二是shellcode_addr + 8处的值其实是被破坏的,需要想办法绕过这里。
如果我们将target_addr设置为某个函数got表地址,那么当程序调用这个函数的时候,会直接执行shellcode_addr处的代码。
这样我们就通过Unlink实现了任意地址读写,看起来很完美,但是这是在没有任何检查的情况下才能实现的。
残酷现实
理想很美好,现实很残酷。实际上Unlink操作时会进行一系列的检测:
Double Free检测:该机制不允许释放一个已经处于free状态的chunk。因此,当攻击者将second chunk的size设置为-4的时候,就意味着该size的PREV_INUSE位为0,也就是说second chunk之前的first chunk(我们需要free的chunk)已经处于free状态,那么这时候再free(first)的话,就会报出double free错误。
next size非法检测:该机制检测next size是否在8到当前arena的整个系统内存大小之间。因此当检测到next size为-4的时候,就会报出invalid next size错误。
双链表冲突检测:该机制会在执行Unlink操作的时候检测链表中前一个chunk的fd与后一个chunk的bk是否都指向当前需要Unlink的chunk。这样攻击者就无法替换second chunk的fd与fd了。
所以前路遥远,只能埋头学习。