Introduction
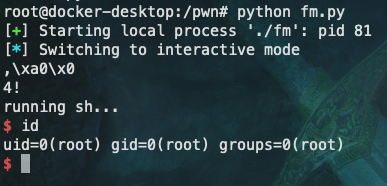
程序运行截图:
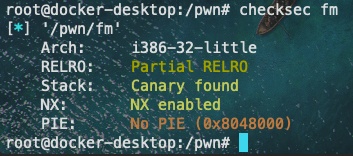
checksec发现存在Canary以及DEP保护:
Analysis
将程序通过IDA打开,首先是main函数:

可以看到主函数里就已经存在system("/bin/sh")的语句,基本思路当然要满足跳转条件,执行该语句。
根据运行结果可以知道这个x在程序中被定为3,我们需要将其改为4。而在printf(&buf)这里存在典型的格式化字符串漏洞,通过该漏洞可以实现任意内存写入。
Vulnerability
解题关键在于了解格式化字符串漏洞,而在了解这个漏洞之前,首先要了解一下printf函数(其他函数类似sprintf、fprintf等print家族函数都会存在同样的问题)。
printf函数用法是printf(“格式化字符串”, 参数…),函数返回值是int类型,返回正确输出的字符个数。如果输出失败,返回负值。参数个数不确定,可以是多个,也可以没有参数。
prtintf函数的格式化字符串常见的有下面几种:
1 | %a 浮点数、十六进制数字和p-记数法(c99 |
还有不常见的%n,会将%n之前打印出来的字符个数赋值给一个变量。此外还有%hn(写入目标空间2字节),%hhn(写入目标空间1字节),%lln(写入目标空间8字节)。
例如这样一个程序:
1 |
|
程序编译运行之后输出的n是4。
接下来就可以去了解一下格式化字符串漏洞了。正确的printf函数用法应该是这样的:
1 |
|
而有时候也会被省略成这样:
1 |
|
两种方式写法上没什么问题,但是当把字符串输入权交给用户时,就会造成严重的问题。考虑这样一个程序:
1 |
|
如果用户输入的不是正常的字符串,而是格式化字符串%x%x,则会输出内存中的数据:
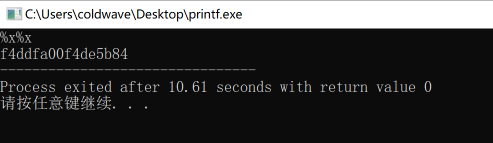
这是由于printf函数并不知道参数个数,在其内部有个指针,用来检索格式化字符串。对于特定类型的格式化字符串,去取相应参数的值,直到结束。所以尽管程序中没有参数,上面的代码也会将输入的fromat string后面的内存当作参数以%x即16进制方式输出,造成内存泄漏的问题。
通过内存泄露问题就要引申到任意内存读取的问题上,当然前提是需要确定局部变量是储存在栈中,这样理论上通过很多个%x就可以读到想要的内存位置。
也可通过%< number>$x是直接读取第number个位置的参数,同样可以用在%n,%d等等。
但是需要注意64位程序,前6个参数是存在寄存器中的,从第7个参数开始才会出现在栈中,所以栈中从格式化串开始的第一个,应该是%7$n。
甚至通过这个漏洞可以实现任意地址写入,需要用到linux自带的printf命令,将shellcode编码转义为字符。(注意用反引号将printf命令括住,反引号在Tab键的上面,反引号内的内容会被当做命令执行。)如果是用scanf输入字符串,则无法使用printf命令,只能对照ascii码表,scanf和命令行输入的shellcode编码不能直接被转义。
例如通过"printf ‘\x41\x41\x41\x41’"将0x41414141这个地址写入内存,下面只需用%s读取对应位置,就能读取以0x41414141为首地址的字符串。
如果用%n就能将0x41414141这个地址指向的值修改,就能造成任意内存的修改,可以将栈中返回地址修改为想要执行的shellcode的首地址等等。
这里要注意ASLR的问题。
PWN
接下来就来继续分析刚开始那道题。
通过Analysis部分的分析,程序中存在格式化字符串漏洞。通过x_addr%[i]$n命令,可以将已经输出的字符个数写入到指定的参数中,这个格式化字符串会在栈上的某处,需要定位x_addr作为printf的第几个参数来确定[i]的值,由于x_addr在32位程序中刚好是4个字节,所以这个格式化字符串刚好能把相应参数变为4。
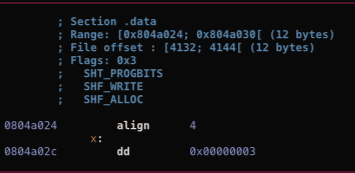
首先是main函数中的x位置,根据下图x_addr应该是0x804a02c:
然后再确定偏移:
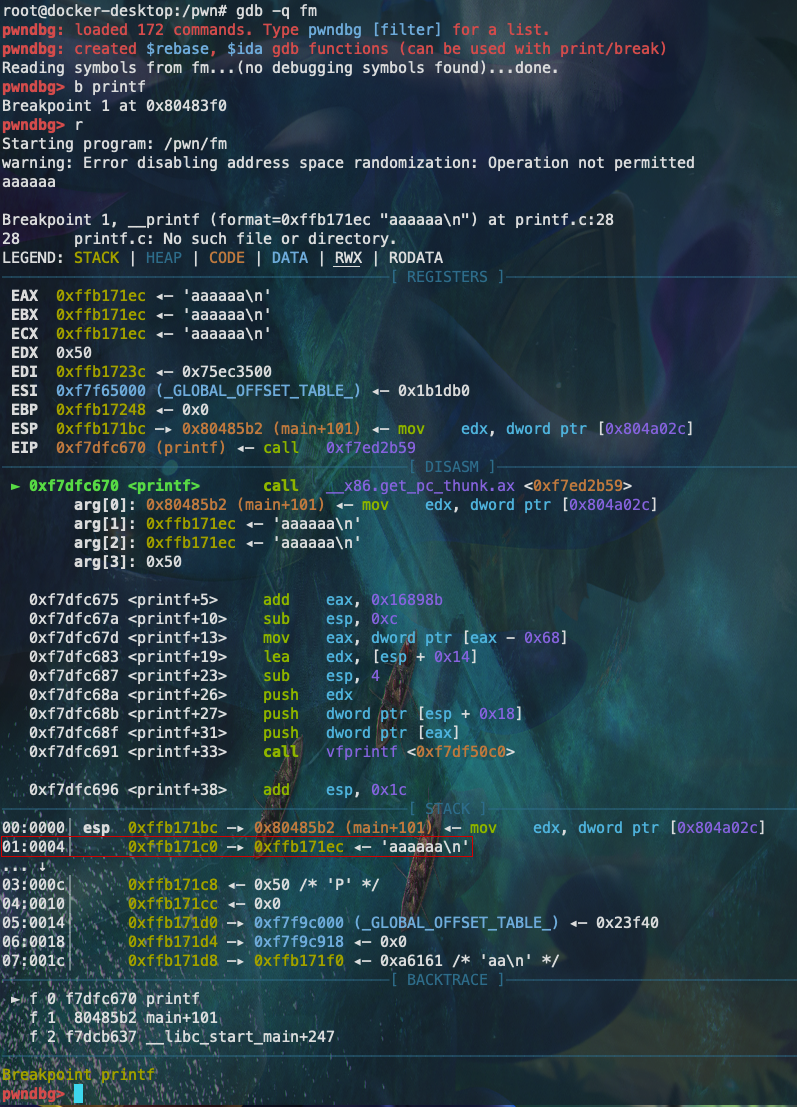
将程序断在printf函数,发现输入的数据“aaaaaa”在栈上地址为0xffb171ec,原来数据的地址为0xffb171c0。两者地址差值便是偏移为44。这个程序是32位程序,每个格式化字符串位4字节,所以偏移数为11。
最后就是写脚本了:
1 | from pwn import * |
脚本本地运行结果: