Info
- 名称:URLNet: Learning a URL Representation with Deep Learning for Malicious URL Detection
- 作者:Hung Le, Quang Pham, Doyen Sahoo, Steven C.H. Hoi
- 原文链接:arxiv
Intro
- 传统的恶意Url检测局限于黑名单,导致难以快速反应,同时无法检测不在黑名单中的未知恶意Url。
- 为了解决传统黑名单检测带来的滞后性,机器学习算法的介入提供了全新的方向。但是传统的机器学习算法依赖于特征提取技术。目前词袋模型作为最常用的语义特征提取技术,在面对恶意Url检测时存在许多挑战。比如难以准确的截取极具特征的字符串片段,无法学习到未知特征等。
Contributions
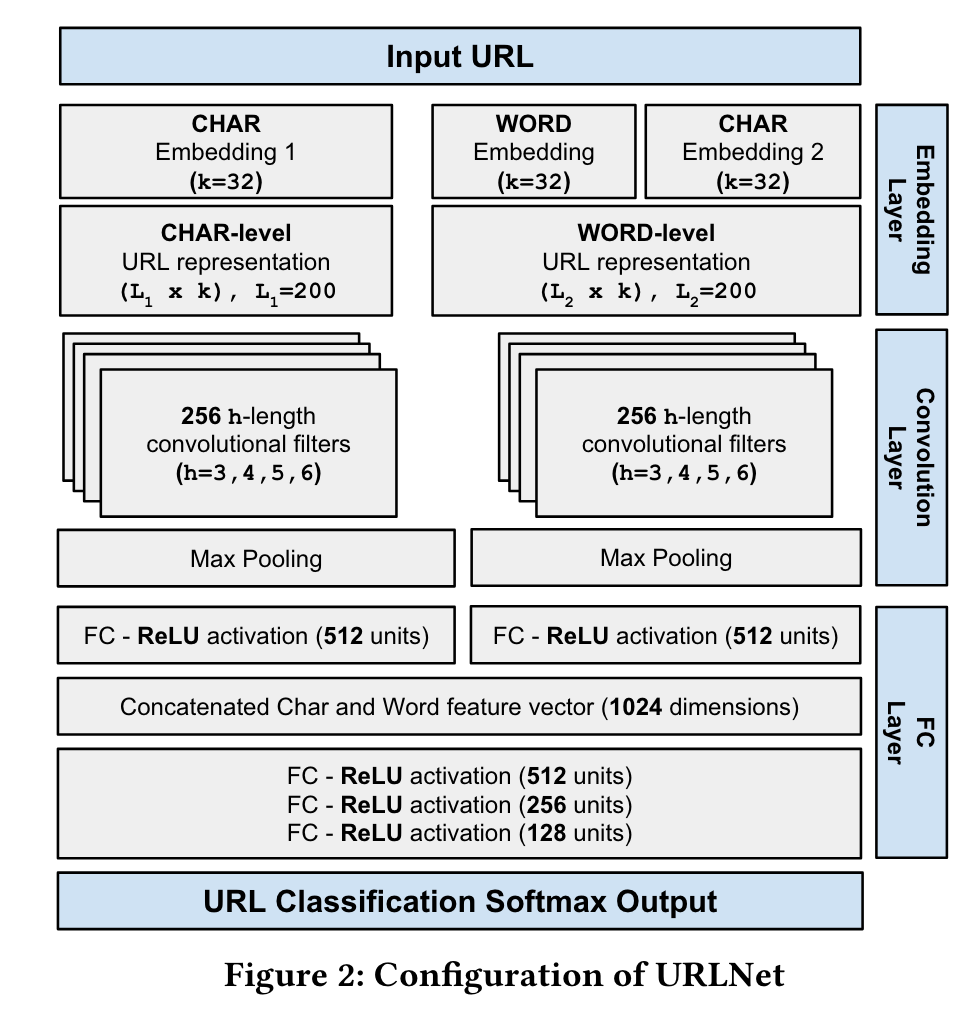
- 论文提出了基于深度学习的恶意Url检测方案URLNet,从字符以及词两种维度分别进行表示,通过CNN网络训练学习,最后结合两种种维度的特征获取结果。
Paragraph
- 样本中的URL统一只保留前200个字节,多余的部分截断,不足的部分用
填充。 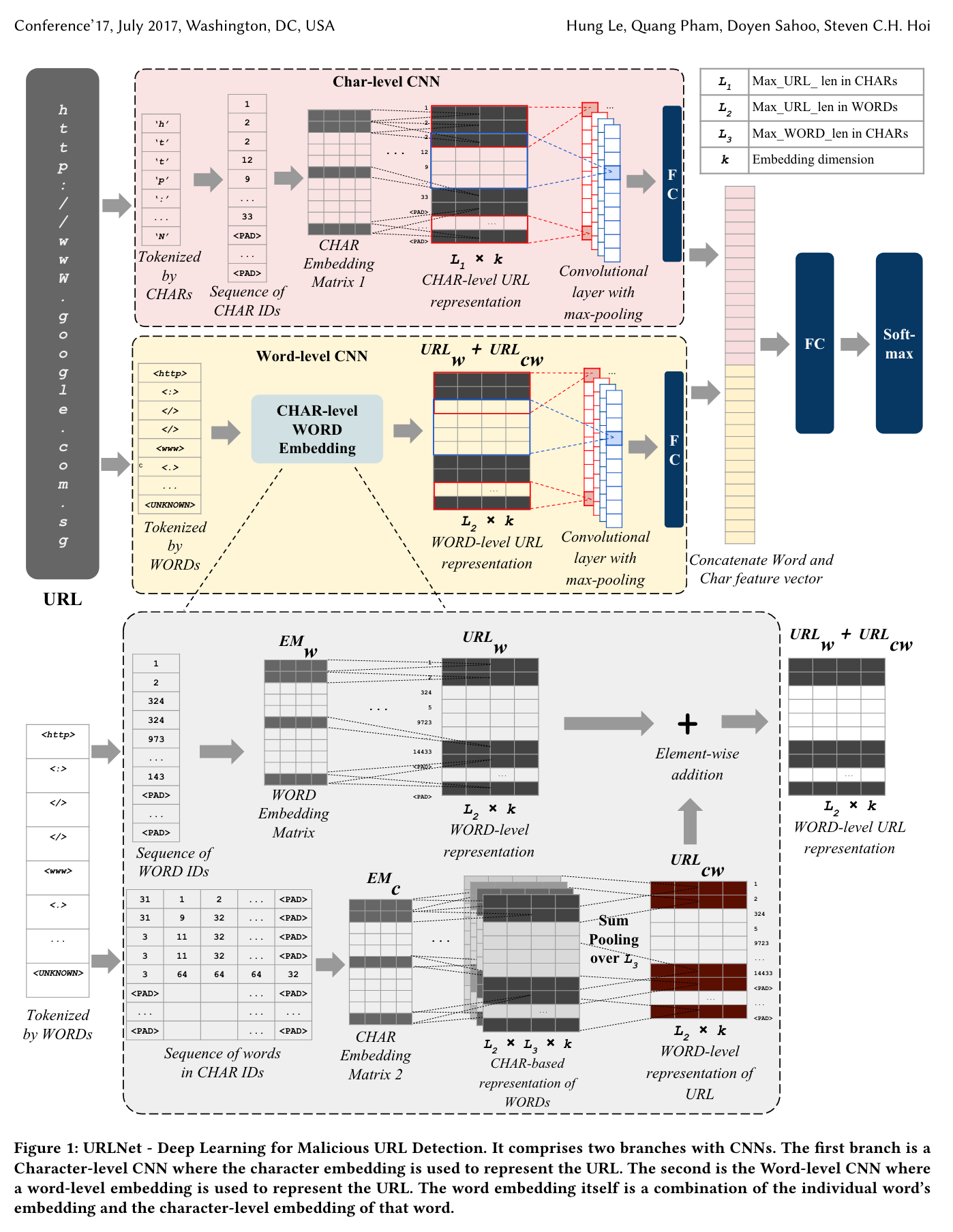
- 特征提取
- Whole URL BoW
- Bag of Words
- 独特词的数量
- URL Component Tokenisation (UCT)。将URL分成主域名,路径,最终路径标识,最顶层域名。对每个部分分别建立BoW字典。
- Position Sensitive & Bigrams (PSB)。特殊字符如域名和路径会被提取出来组成大的字符,同时标记其相对位置。
- Character Trigrams。通过3个字符大小的滑动窗口处理URL中的域名生成新的tokens。
- 其他统计学特征:URL长度,hostname长度,URL中点的个数等。这些特征由具备专业知识的人员设计。
- Whole URL BoW
Comments
- 文章提出了一种全新的基于语义的深度学习恶意Url检测模型,提供了从单个字符及单个词两种角度结合的分析视角,值得借鉴。
- 在从词的角度进行分析的网络中,论文在传统词袋模型之外提出了一些新的特征处理方法,并通过实验结果验证了有效性。